One critical thing for any environment, in my opinion, is monitoring. Being able to detect problems and get an understanding of them is crucial to solving them.
One thing that is important to monitor is your network. This is not just an important to get a sense of its health an performance, though. Detecting when client machines talk to potentially malicious hosts is a pretty quick way to pick up on security concerns.
Technologies at Play
Monitoring networks isn’t a new problem, and most routers like OPNsense have a fairly basic set of monitoring tools built in. These give a basic picture, but I’d like to experiment with some deeper analysis and was really impressed with the level of data some tools can give.
Sometimes, these routers can also run more advanced monitoring packages on them, but I wanted to reduce the workload on my firewall if possible. It already is doing routing for several local subnets and IDS, so analytics and alerting just seemed like too much.
If you want to send data to another host, there’s a number of ways to do this too. You can just route the traffic through as an extra gateway, but this would cause issues if it went offline. You can use physical things like port mirroring or taps as well, but OPNsense actually has software to fix this problem built in.
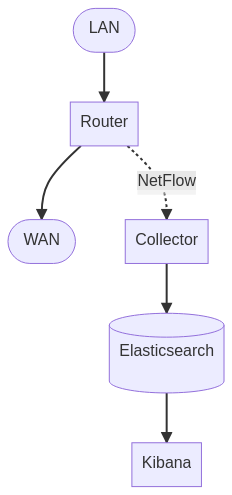
The protocol is called NetFlow, and was originally developed by Cisco. The idea is to have devices on the network transmit traffic patterns (called “flow records”) to a central monitoring server called a “collector”. The collector’s job is to then take the data, store it in some database, and then let us view the data. Elastiflow will collect our data here and Elasticsearch and Kibana will store our data and let us view it.
Here’s what our setup will look like. We’ll have our router collecting the NetFlow data and send it off to our collector instance and a database. Keep in mind this takes place completely off the router. Once the NetFlow data is sent, our router’s responsibility is over.
Challenges
Elastiflow is a dual-licensed product, and their website does a poor job of telling you this. They’re very much interested in selling you their enterprise grade offering, but for a homelab their free option works. Their documentation is also somewhat sparse, so getting it setup can be a chore.
They distribute their collector via Docker and sample configurations, so I adapted their examples and samples to get things working. For my small setup, I just run everything on one node with a single Elasticsearch node. Larger setups can warrant more nodes, but for me this works.
The Actual Setup
There’s a few files we need to create, so I opted to create a proper GitHub repository for things.
You’ll need Docker and Docker Compose to run this, follow Docker’s docs to install those.
I recommend a dedicated machine on your network to handle this, but it’s all
Docker based so you can run this anywhere. This does require the container to
have a host network driver, so you can’t run other containers that require
host network access.
Code and Directories
I setup a directory on my system in /opt/elastiflow to house things, and
cloned that repository to it:
mkdir /opt/elastiflow
chown you:you /opt/elastiflow
git clone https://github.com/grumpy-systems/elastiflow-example.git /opt/elastiflow
We now need to fix the Elasticsearch data directory. Since Elasticsearch doesn’t run as root in the Docker container, it won’t be able to read or write to the data directory automatically created (especially if you ran the above steps as root).
chown 1000:1000 /opt/elastiflow/data/es
Systemd
If you want the collector to start automatically, install the Systemd unit file. This creates a new service on your server that will be started at boot and start the required containers:
cp /opt/elastiflow/elastiflow.service /etc/systemd/system/.
systemctl enable elastiflow.service
Once installed, you can use systemctl to start, stop or restart things:
systemctl start elastiflow.service
systemctl stop elastiflow.service
systemctl restart elastiflow.service
Manual Startup
If you want to start things manually for testing, you’ll need to let Elasticsearch start first before starting the collector. In my experience, the collector immediately starts to create templates that fail, and that causes the collector to sit in an error loop.
I added a start.sh script for this reason. It starts the Elasticsearch
container then waits two minutes before starting the rest. If you want to watch
Elasticsearch start, use docker-compose up elasticsearch to just start that
container.
Setting up Kibana
Kibana needs some dashboards and objects added. In the repository, there are
two ndjson files: one for light mode and one for dark mode. Pick the one you
want, and download it to your workstation.
Go to Kibana (http://ip-of-your-collector:5601) and navigate to Stack Management in the left menu. Then in the new left menu, navigate to Saved Objects. Select Import and upload the file you downloaded. This creates a number of dashboards for your usage.
To go to the overview now, go to Analytics > Dashboards in the left menu and select “Elastiflow: Overview” in the list. You should see an empty dashboard with links to various Elastiflow dashboards.
Setting Up a Retention Policy
Once we’re collecting data, Elasticsearch will very likely fill up and need pruned at some point. In my environment, each day of logs generates about 2-3 GB of data that’s stored in Elasticsearch.
To keep things from filling up and never getting deleted, we’ll want to add a new lifecycle policy for all our new Elastiflow indexes.
To do this, navigate to Stack Management again, and go to “Index Lifecycle Policies.” Create a new policy and name it something useful (I called mine Elastiflow_Clean_14d). The only phase you’ll need to turn on and set is the “Delete Phase”, and set the timing to whatever retention you’d like. In my case, I set it for 14 days.
Once it’s created, find it in the list of policies, click “Actions” and “Add policy to index template.” Select the “elastiflow-flow-ecs-1.7-1.4” option. This ensures that all new indexes will have the 14 day retention set up by default.
Configuring OPNsense
OPNsense already has a NetFlow exporter built in, so we just need to activate it.
Navigate to Reporting -> NetFlow in the left menu. Set things up as required:
- Listening Interfaces - Pick the interfaces you want to get stats for.
- WAN Interfaces - Pick your WAN interface. This is needed to fix NAT reporting issues.
- Capture Local - Doesn’t matter, but default is unchecked.
- Version -
v5 - Destinations - Add the IP and port (9995) of your collector machine.
That’s It!
Once your OPNsense instance is sending data, it’ll get uploaded into Elastiflow and the dashboards in Kibana in short order. There are more features that aren’t setup yet in my example, but I’ll continue updating it as I find time. For now, this should give you some decent monitoring.
One big advantage I see is that the data is just stored in Elasticsearch, so we can query it and create custom dashboards and monitoring based off this database. I see some pretty cool use cases I’ll be sure to share.